
When I first published a version of this guide, the underwriting world was a different place. The conversation was about whether AI belonged in underwriting at all. In 2026, the conversation has changed: AI is in production at most top-quartile carriers, the NAIC AI Model Bulletin has been adopted in roughly half of U.S. states, and the senior underwriter shortage has moved from a forecasting curve to a present-tense operations problem. This guide is a full rewrite for that environment.
I’m Marcin Nowak. I co-founded Decerto two decades ago and have spent that time embedded in U.S. and European insurance technology - building rules engines, deploying AI for insurance, and helping P&C carriers replace fragmented submission workflows with modern underwriting workbenches. What follows is the version of this guide I would hand to a new Chief Underwriting Officer who walked into my office and asked, “What do I actually need to know before I sign off on a workbench RFP?”
Why an underwriting workbench matters in 2026
I worked with a Northeast specialty carrier whose CUO ran a quiet experiment. He pulled twelve underwriters into a room, handed them the same eligibility manual, and asked them to evaluate the same twenty submissions. He found 47 distinct interpretations of a single eligibility rule across those twelve underwriters. Same guidelines. Same training. Same desk. 47 different applications of one rule. Multiply that by the several hundred rules in a typical commercial underwriting manual, and what you have is not a portfolio that is being underwritten - it is a portfolio that is being interpreted.
That is the problem an underwriting workbench solves at root. Not “speed” and not “efficiency,” though those follow. The core problem is consistency: a portfolio’s loss ratio is a function of every individual decision being made against the same risk appetite, and that consistency does not exist when the appetite lives in PDFs, Word documents, and the working memory of senior underwriters.
Three forces converged in 2026 to make this a CUO-level priority rather than a back-office IT project.
The first is regulatory. The NAIC adopted its AI Model Bulletin in December 2023. By the end of 2025, approximately 24 NAIC jurisdictions had adopted the bulletin, and the NAIC’s December 2025 statement noted that over half of all states have adopted this or similar guidance. The NAIC AI Systems Evaluation Tool pilot is now running through September 2026 in twelve states - California, Colorado, Connecticut, Florida, Iowa, Louisiana, Maryland, Pennsylvania, Rhode Island, Vermont, Virginia, and Wisconsin. If your underwriting workbench cannot produce a model card, validation report, bias testing artifacts, and a per-decision audit trail on demand, you are 12-18 months behind where regulators already expect you to be.
The second is demographic. The U.S. Bureau of Labor Statistics projects the insurance industry will lose approximately 400,000 workers through retirement and attrition by 2026, with half of the current workforce expected to retire within the next 15 years. The standard framing - “we have a hiring problem” - misses what is actually happening. One in four underwriters is over 50, and the average insurance professional is in their mid-50s. The judgment those people carry is not in any rating table. When they retire, that judgment retires with them unless it has been codified somewhere. A workbench is the somewhere.
The third is competitive. Early adopters of agentic AI and underwriting automation are reporting 40%+ reductions in claims cycle times and 36%+ improvements in underwriting efficiency, and McKinsey’s research on commercial P&C underwriting documents that even leading insurers can capture loss ratio improvements of three to five points and new business premium increases of 10 to 15% through digitized underwriting. In a softening rate environment - AM Best projects net premiums written to grow around 4% in 2026, down from 6.1% in 2025 and 8.7% in 2024 - three to five points of loss ratio is the difference between a combined ratio that compounds shareholder value and one that drains it.
This guide covers the eight specific underwriting pain points a modern workbench solves, the six vendors competing for your evaluation, the explainability and NAIC compliance requirements you cannot postpone, the 14-month implementation roadmap that separates successful deployments from failed pilots, and the build-vs-buy-vs-partner decision framework that determines which path fits your portfolio.
What an underwriting workbench actually is
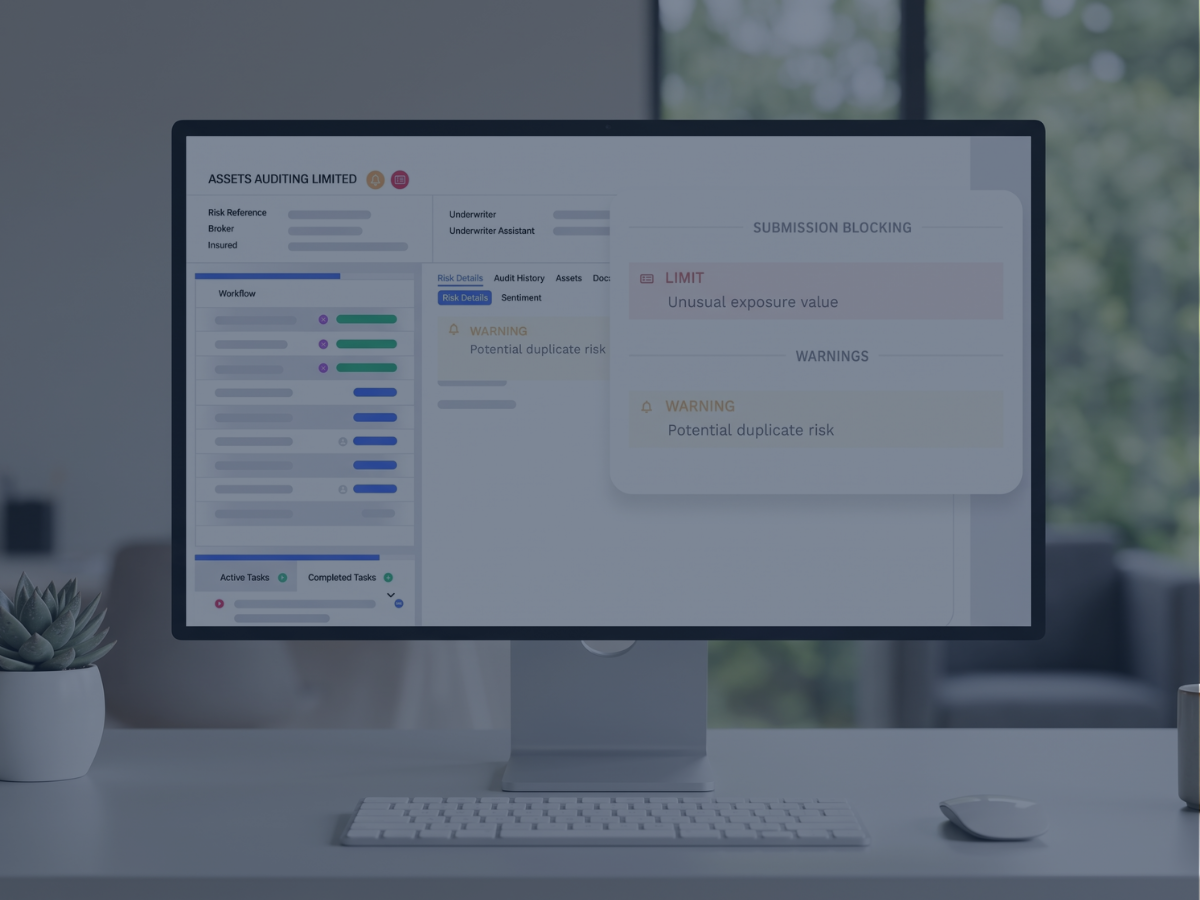
An underwriting workbench is a unified workspace where insurance underwriters intake submissions, evaluate risks against rules and AI scoring, document decisions with a full audit trail, and route policies to bind - all without leaving a single application. A modern workbench replaces the patchwork of spreadsheets, PDF guidelines, document management folders, third-party data lookups, and email threads that fragmented underwriting workflows for the past two decades.
That is the headline definition. The architecture underneath has seven structural components, and which of these your vendor handles well - versus which they hand-wave - is the variable that determines whether your deployment succeeds.
The rules engine is the heart. It encodes underwriting guidelines as executable logic, applies them consistently to every submission, flags exceptions for human review, and - in modern workbenches - lets your CUO and chief underwriters change rules without filing an IT ticket. Higson, our rules engine for underwriting, is built on this principle: the people who own the underwriting outcome should also own the rules that produce it. You can see how Higson handles rule authoring at higson.io/insurance/underwriting.
The risk scoring layer combines rules-based logic with machine learning models. Rules handle the bright-line decisions (declines, mandatory referrals, capacity limits). ML adds pattern recognition the rules cannot capture - fraud signals, latent exposure correlations, segment-level loss propensity. The combination is more defensible to a regulator than pure black-box ML and more accurate than pure rules.
The document automation layer handles unstructured inputs: ACORD forms, loss runs, broker emails, inspection reports, financial statements. Modern workbenches use OCR, NLP, and increasingly generative AI to extract structured data from these documents and populate the submission record. A senior commercial lines underwriter might spend 60-70% of their day extracting information from documents, with only 30-40% of the day going to actual underwriting judgment. Document automation inverts that ratio.
The decision support and audit trail records every decision: what rule fired, what data the model saw, what the underwriter overrode, and why. This is not optional in 2026. It is the artifact you produce when a market conduct examiner asks how you made a specific underwriting decision.
The external data integration layer connects to ISO, CLUE, D&B, Verisk hazard data, weather, telematics, and increasingly geospatial CAT models. The integrations are commodity. The differentiator is whether the workbench applies the data inside the rule logic at submission time, or whether it dumps the data into a separate screen and asks the underwriter to reconcile.
The explainability layer turns model outputs into human-readable rationales - why a risk was scored where it was scored, which features drove the score, and what would have to change to flip the recommendation.
The Excel integration is unglamorous and load-bearing. Actuaries live in Excel. Pricing committees review books in Excel. A workbench that breaks the Excel handoff creates a parallel workflow that defeats the unification it was supposed to deliver.
What separates a 2026 workbench from a 2020 workbench is not any one of these components in isolation - it is human-in-the-loop AI architecture across all of them. The system recommends. The underwriter decides. The system records both. That distinction matters because the dominant misconception that delayed too many CUOs from greenlighting workbench projects from 2021 through 2024 was the belief that AI was about replacing underwriters. It was not. It is augmentation. Every serious workbench in market in 2026 is built on that premise.
The 8 underwriting pain points a workbench solves
The remainder of this guide goes deep on architecture, vendors, and implementation. This section is the one most CUOs care about: which specific operational problems are you solving, and what does a modern workbench actually do about each one. The eight pain points below are the ones I see in nearly every U.S. P&C carrier engagement, and they map directly to the deep-dive Core articles in this content cluster.
Pain 1: Guidelines fragmented across PDFs, Word, and tribal memory
The 47-interpretations example I opened with is not unusual. It is the median state of underwriting authority documentation in U.S. carriers. The eligibility manual is in PDF. The credit policy is in Word. The appetite memo from last quarter is in someone’s inbox. The committee decision from the August meeting is in a Slack thread. The actual day-to-day interpretation lives in the heads of senior underwriters, who reconcile the contradictions on the fly.
A modern workbench replaces that with a single rules engine where every guideline is encoded as executable logic, every change is versioned, and every decision can be traced back to the specific rule version that produced it. The CUO no longer has to wonder whether the appetite memo from August has actually reached the field. It either fired on the relevant submissions, or it did not, and the audit log will tell you which.
For the full breakdown of how a rules engine reshapes underwriting authority - including the difference between authoring tools, governance workflows, and rule testing approaches - see our deep dive: Top features to look for in an underwriting workbench solution.
Pain 2: No real-time portfolio visibility
A CUO at a Florida specialty carrier described the problem to me this way: “I find out about my portfolio at month-end close. By the time I see the report, the exposure I’m worried about has already accumulated for three weeks.” That is the structural problem of running a portfolio off legacy data warehouses that refresh on overnight or monthly batch cadence.
CAT season makes this acute. Hurricane forms, the wind speed forecast tightens, and the CUO needs to know - right now - how much TIV the carrier has on the Gulf Coast within X miles of the projected track, broken out by deductible structure and reinsurance attachment. Month-end data does not answer that question. Real-time portfolio monitoring does.
A modern workbench feeds an operational data store (ODS) with every bind, endorsement, and cancellation as it happens, and surfaces it through dashboards aggregated to the dimensions a CUO actually thinks in: line, segment, geography, broker, hazard, accumulation. Alerting fires when concentration thresholds are breached, not when month-end reports get produced.
Pain 3: Black-box AI without explainability
A CUO at a Midwest commercial carrier showed me an AI risk score his vendor had deployed. He asked the vendor’s customer success rep why a specific submission scored where it scored. The rep said: “The model is proprietary.” That is the answer that ends careers in 2026. Technical explainability - SHAP values, LIME, partial dependence plots, counterfactuals - is a body of methods. Regulatory explainability is a different deliverable: a written narrative an examiner can adopt as their working understanding of the model and use as the basis for a decision on a rate filing.
A modern workbench implements both. The data science team uses SHAP and LIME for model validation. The workbench produces, for every consequential decision, a human-readable rationale in underwriting language: which factors moved the score, by how much, and what the threshold logic was. That rationale is what the CUO points to when an applicant complains, when an agent escalates, or when a state DOI sends a letter.
Pain 4: Senior underwriter knowledge walking out the door
This is the pain CUOs feel most personally. A senior specialty underwriter retires with 25 years of judgment that exists in no manual, no rating table, and no training dataset. The institutional response - “we’ll do knowledge transfer sessions” - captures roughly 10% of what that person actually knows, because most of the judgment is unconscious. When asked to document their workflow, experienced underwriters who thought they followed five steps were found to follow 15 nuanced processes.
A workbench changes the unit of capture. Instead of asking the senior to teach a junior, the carrier captures the senior’s actual decisions over a period of months, codifies the patterns into executable rules and ML features, and validates those rules against the senior’s continued judgment. By the time the senior retires, their 25 years of pattern recognition lives in 800+ executable rules, dozens of model features, and a well-documented appetite framework. They don’t leave with the knowledge. They leave because the knowledge has finally been written down.
This is not “AI replaces underwriters.” It is institutional memory infrastructure. For the full discussion of why the replacement framing has been counterproductive and how augmentation models actually work, see: Will AI replace underwriters? The 2026 reality.
Pain 5: Adverse selection - bad risks getting through
Adverse selection is the structural enemy of every carrier’s loss ratio. The mechanism is simple: when your underwriting consistency is uneven, the brokers learn which underwriters approve marginal risks, and they route those risks to those underwriters. The carrier writes the bad business its competitors declined, and the loss ratio reflects it.
A modern workbench attacks adverse selection through three mechanisms. First, rule consistency removes the “easy underwriter” path - every submission is evaluated against the same rule set regardless of which underwriter receives it. Second, AI risk scoring adds pattern detection that humans miss: subtle correlations between policyholder characteristics and loss propensity that don’t appear in any single rating factor. Third, fraud detection at quote - flagging submissions that match known fraud patterns before bind, not after a claim - removes a category of bad business that traditionally only surfaced in claims data months later.
Combined and loss ratio improvement using AI ML models has been reported as 3-6 and 2.1-4.2 percentage points respectively, with anti-selection portfolio improvement of 10-15%. For the deep dive on AI risk scoring architecture and pre-bind fraud detection, see: How an AI-powered underwriting workbench improves efficiency in risk assessment.
Pain 6: 4-month IT backlog for rule changes
The Chief Underwriting Officer at a regional commercial carrier described the workflow: “I see a deteriorating segment in the portfolio. I want to tighten eligibility on it. I write a memo. The memo goes to product. Product writes a requirement. The requirement goes to IT. IT puts it in the next quarter’s release. The change ships four months after I identified the problem. By then the segment has compounded another quarter of bad business.”
This is the structural argument for no-code rules. When your CUO and chief underwriters can author and deploy rules directly - with proper governance, testing, and rollback - the change cycle goes from quarters to days. Higson is built on this principle. Rule changes flow through a governance workflow (drafted, peer-reviewed, tested in sandbox, approved, deployed) with full version history and rollback. No sprint planning. No release train. No compromise on auditability.
Pain 7: NAIC compliance and regulator audit readiness
The NAIC AI Model Bulletin compliance section later in this guide covers the substantive requirements. The operational pain is different: when a state DOI sends an inquiry letter asking the carrier to document its AI governance program for a specific decision, can the compliance team answer in hours, or does it take six weeks of forensics across email threads, ticket systems, and underwriter notes?
A modern workbench answers in hours. Every decision has a complete audit record. The AI governance documentation - model cards, validation reports, bias testing - sits in the same system as the decisions it governs. The compliance officer pulls a report. The examiner gets what they asked for. The examination cycle compresses.
For the full breakdown of regulatory underwriting in the post-NAIC AI Bulletin environment, see: How an underwriting workbench strengthens regulatory compliance.
Pain 8: Decision time too long for simple risks
Not every submission needs senior judgment. A clean BOP renewal with a stable five-year loss history and no exposure changes does not need to sit in an underwriter’s queue for four days. A modern workbench handles those submissions through straight-through processing (STP): rules engine evaluates eligibility, AI confirms risk score is within appetite, system binds and issues the policy. The senior underwriter never sees it. Their capacity goes to the complex risks where their judgment actually changes the outcome.
I have seen carriers move from a 12% STP rate to 62% in 18 months with the right workbench architecture. The capacity that frees up does not lead to layoffs - it leads to senior underwriters spending more time on the specialty risks that justify their compensation.
For the full discussion of STP architecture and AI risk assessment for routine submissions, see: How an underwriting workbench streamlines risk assessment.
Core capabilities of a modern underwriting workbench
The eight pain points map onto seven core capabilities. Every vendor will claim to have all seven. Whether they actually do is the work of due diligence. What follows is the framework I use to evaluate workbench RFP responses.
Rules engine with CUO-controlled authoring
This is the load-bearing capability and the one most vendors get wrong. A serious rules engine has four properties: a rule authoring environment that a chief underwriter can use without an engineer present, a governance workflow with versioning and approval gates, a sandbox where new rules can be tested against historical submissions before deployment, and a rollback capability when a rule produces unintended results. Higson is built specifically for this - the CUO and chief underwriters own the rule authoring authority, the governance workflow ensures compliance review before deployment, and the rollback path is one click. You can request a Higson demo.
Hybrid risk scoring (rules plus ML)
Rules handle the bright-line decisions that need to be defensible to a regulator and consistent across the portfolio. ML handles the pattern detection that rules cannot capture - subtle correlations across many features that move risk scores within the rule-defined boundaries. The hybrid pattern is what most P&C carriers will run in 2026 and beyond. Pure rules are too brittle for high-volume personal lines. Pure ML is too opaque for specialty commercial. The hybrid handles both.
Document automation across ACORD, loss runs, and unstructured submissions
The capability is not “OCR.” Every workbench claims OCR. The differentiator is the precision of structured extraction across the document types your underwriters actually receive: ACORD forms with broker-specific deviations, loss runs from a hundred different carriers each with their own format, broker emails with pasted Excel content, inspection reports with photos. The vendor’s demo will show clean extraction on a clean ACORD. The reality of your inbox is messier. Insist on extraction quality testing on your own document set during the POC.
Decision audit trail at the per-submission level
Every decision the workbench makes - every rule that fired, every model output, every underwriter override - must be recorded and queryable per submission. This is the artifact the regulator examines. It is also the artifact you use internally to debug surprising loss ratio results: when the portfolio underperforms, you reconstruct which decisions led to which outcomes.
External data integration with Verisk, ISO, CLUE, D&B, weather, and telematics
Integration is a commodity capability. The difference is whether the data arrives in time for the rules engine to use it at submission, versus arriving in a separate screen the underwriter has to consult. Modern workbenches treat external data as an input feature in the rule and model logic, not as a sidebar lookup.
Explainability layer translating model outputs into underwriting language
The data science team uses SHAP. The CUO uses sentences. The explainability layer is what bridges them: model output → feature importances → human-readable rationale in the language of underwriting. “Declined because credit score below 620 AND property in CAT Tier 4 zone AND 3+ liability claims in last 5 years.” Not “SHAP value -0.34 on feature credit_score_normalized.”
Excel integration for actuarial and pricing workflows
Actuaries live in Excel. So do pricing committees. A workbench that pulls clean rate adequacy reporting, segment performance pivots, and exposure aggregations into Excel - without manual export-and-reformat - preserves the workflow that actuarial teams have spent decades optimizing. A workbench that breaks that handoff creates parallel data infrastructure and erodes adoption.
Rules engine vs machine learning: when to use each
This is the most-misunderstood architectural decision in modern underwriting. Vendors have an interest in pushing whichever approach matches their product. The honest answer is that nearly every P&C carrier in 2026 needs a hybrid, with the rules-to-ML balance varying by line of business, regulatory environment, and risk appetite.
The reasoning behind the matrix is straightforward. Specialty and complex commercial lines have lower submission volumes, more idiosyncratic risks, and harder regulatory documentation requirements. Pure ML cannot handle the specificity of, say, a trucking program with a 40-vehicle fleet operating in five states with a unique mix of perishable and hazmat cargo - there isn’t enough comparable historical data to train a stable model on. Rules can encode the senior underwriter’s judgment about what makes that risk acceptable. ML adds pattern detection on top of the rules-defined acceptance envelope.
Personal lines and high-volume small commercial flip the balance. Auto, homeowners, BOP - these run at scale with abundant historical loss data. ML adds material accuracy that rules cannot match. But even here, rules carry the regulatory documentation: which factors went into the decision, in what order, with what weights. The rules layer is what you show the state DOI.
Higson is rules-first by design, with ML extensibility through our AI for Insurance product. The CUO retains authority over the rule layer that defines appetite, eligibility, and capacity. The ML layer adds pattern detection within those boundaries. The architecture is hybrid by intent - not because we couldn’t build pure ML, but because pure ML is the wrong answer for most P&C carriers in 2026, even the ones writing high-volume personal lines, once you account for NAIC compliance and CUO control.
The agentic AI row deserves a note. Generative AI agents that receive a submission and immediately extract key data points, check against appetite guidelines, flag immediate declinations, and process loss runs in seconds are moving from pilot to production at carriers in 2026. The capability is real. The governance frameworks are still emerging. For specialty commercial, I currently advise carriers to deploy agentic AI for submission triage and document synthesis, but not for autonomous bind authority on consequential risks. That line will move over the next 24 months.
Underwriting workbench vendor comparison: Guidewire, Duck Creek, Sapiens, Majesco, Verisk, Decerto/Higson
The vendor comparison below is the one I wish someone had handed me before my first workbench RFP. Every vendor lists a similar set of features. The differentiation is in the seven criteria that actually predict deployment success.
A few notes on what the table is and is not saying.
Guidewire and Duck Creek dominate the U.S. P&C market for full policy administration suites. Among the top companies, Guidewire Software stands out for its comprehensive underwriting workbench platform, which integrates seamlessly with its broader insurance suite, while Duck Creek Technologies is another prominent player, known for its cloud-based underwriting workbench solutions tailored to property and casualty insurers. If you are running Guidewire PolicyCenter as your PAS, you are not going to rip out Guidewire to put in a different workbench. The right question is whether the workbench you put on top of Guidewire is Guidewire’s own UW module - with its 18-36 month implementation cycle and IT-controlled rule changes - or whether it is a workbench that layers on top of Guidewire and lets your CUO control the rules. Higson is designed for the latter scenario. We have integrated with Guidewire, Duck Creek, and Majesco at multiple carriers without replacing the underlying PAS.
Sapiens, Majesco, and Verisk each occupy a different niche. Sapiens has strong life insurance presence and is expanding in P&C. Majesco focuses on cloud-native deployment for mid-tier and MGA business. Verisk is best understood as a data layer - their workbench-adjacent products are about getting their industry data into the underwriting decision, not about replacing the underwriter’s workspace.
The Decerto/Higson differentiation is structural rather than feature-by-feature. We were built around one observation: in carriers where the CUO and chief underwriters control rule authoring directly - with proper governance - change cycle times go from months to days, and underwriting consistency improves materially without sacrificing audit defensibility. In carriers where rule changes go through IT, neither happens. Higson is the rules engine designed for the first model. If you are evaluating a workbench, the question I would force the vendor to answer is: “Show me the chief underwriter authoring a rule change, taking it through governance, and deploying to production, in real time, on this call.” If they cannot, the rule layer is IT-controlled regardless of what the marketing deck says.
For our full positioning and pricing approach, see https://www.higson.io/
Implementation roadmap: 14 months from kickoff to production
The 14-month roadmap below is the one I have seen succeed across U.S. P&C carriers in the 500-2,000 FTE range, writing specialty or commercial lines, with existing PAS infrastructure they need to integrate with rather than replace. Faster timelines exist for specific scopes (e.g., a single-line MGA deploying STP for one product). Slower timelines also exist (Guidewire’s full PAS replacement is genuinely 18-36 months). The 14-month arc is the realistic median for a workbench deployment that delivers production value.
Months 1-3: Discovery, requirements, integration assessment
The first quarter is not about technology. It is about portfolio outcomes. The carrier articulates which loss ratio segments need to improve, which speed-to-market constraints are binding, which regulatory pressures are imminent, and which underwriter retirements are scheduled. Those answers drive the requirements document.
The integration assessment maps the existing landscape: what does the PAS look like, where does ACORD intake currently land, which third-party data feeds are in production, what does the actuarial Excel workflow require. Common failure: skipping this and discovering integration debt in month 9.
Months 4-6: Configuration sandbox, rule encoding, integration build
The configuration phase is where senior underwriters and product managers sit with the implementation team and encode rules, workflows, and decision routing into the workbench. This is heavy lift. A single specialty line might require 200-400 rules to encode the eligibility, capacity, pricing, and referral logic that currently lives in PDFs and the heads of senior underwriters.
The integration build runs in parallel: PAS connections, document automation pipelines, external data feeds, Excel reporting handoffs.
Common failure: under-resourcing the rule encoding work and treating it as a side task for the product team. It is the side task that determines whether the workbench actually replicates your underwriting authority correctly.
Months 7-9: User acceptance testing, parallel run, user training
UAT is where the rules and integrations get tested against real submissions. A parallel run - where new submissions go through both the legacy workflow and the new workbench - is the gold standard. It surfaces every edge case the rule encoding missed and every integration assumption that was wrong. Plan for it. Carriers that skip parallel run typically discover problems in production three months later, when rebuilding the trust of senior underwriters costs more than the parallel run would have.
User training is where senior underwriter buy-in is won or lost. The training has to acknowledge that the workbench changes how they work, has to demonstrate that the system supports rather than overrides their judgment, and has to give them direct paths to escalate when the workbench gets something wrong. A workbench that senior underwriters do not trust will not get used regardless of how well it was implemented.
Months 10-12: Phased production rollout
Production rollout is phased by line, by region, or by underwriter cohort - never all at once. The first cohort is the senior underwriters who have been involved in the configuration. They become the internal advocates for the broader rollout. Phased rollout also limits the blast radius if a configuration issue surfaces in production: you fix it for ten underwriters, not five hundred.
Months 13-14: Optimization and ML model deployment
The final phase is where the static rules engine deployment gets ML augmentation. By month 13, you have several months of clean operational data flowing through the workbench. That data is the training input for the ML scoring layer. Deploying ML earlier, before the workbench has produced clean structured data, is the most common reason ML projects fail in underwriting.
Common implementation failures
Across two decades of deployments, the failure modes are remarkably consistent.
The first is starting with technology rather than portfolio outcomes. The RFP runs against features rather than against loss ratio improvement targets, and the project ends up optimizing for the wrong thing.
The second is skipping historical data validation. The carrier deploys ML models without first validating them on five years of the carrier’s own data. The models look fine in vendor benchmarks. They underperform on the carrier’s specific portfolio mix.
The third is underestimating change management for senior underwriters. The technology works. The senior underwriters refuse to use it. The portfolio runs in parallel for years.
The fourth is deploying black-box ML without an explainability layer. The first regulator inquiry exposes the gap. Compliance retrofitting in production is six times more expensive than building it in from the start.
The fifth is selecting a vendor without specialty lines expertise for a specialty book. The vendor configures the workbench to fit their reference architecture, which was built for personal auto. The specialty underwriters find the workbench actively gets in the way of how their actual lines work.
NAIC AI Model Bulletin compliance for underwriting workbenches
The NAIC adopted the Model Bulletin on the Use of AI Systems by Insurers in December 2023. By August 2025, S&P Global reported 24 NAIC jurisdictions had adopted the bulletin, and the NAIC’s December 2025 statement confirmed that over half of all states have adopted this or similar guidance. The trajectory is clear, and accelerated in March 2026 when the NAIC published its formal Issue Brief on AI regulation and launched the AI Systems Evaluation Tool pilot in twelve states running through September 2026. If your underwriting workbench cannot produce model documentation, validation reports, and bias testing on demand, the regulatory deadline is not “someday.” It is now.
Three regulatory developments matter for workbench architecture in 2026.
The first is the AI Systems Evaluation Tool pilot. Carriers in California, Colorado, Connecticut, Florida, Iowa, Louisiana, Maryland, Pennsylvania, Rhode Island, Vermont, Virginia, and Wisconsin should expect inquiries through September 2026. The tool is essentially a structured questionnaire regulators use to examine an insurer’s AI governance program. The questions are not about whether you have AI. They are about whether you have documented governance over the AI you have. A workbench with native model card generation, validation reporting, and bias testing artifacts answers the questionnaire by exporting reports. A workbench without those artifacts forces the carrier into months of forensic documentation work after the inquiry arrives.
The second is the NAIC Third-Party Data and Models Working Group, which spent its March 2026 session sketching the contours of a vendor registry framework. Even with the registry, state insurance departments have signaled they will treat it as a prerequisite, not a substitute, for the carrier’s own diligence file. The 2023 NAIC Model Bulletin already places the diligence obligation on the carrier. Bulletin Section 4 requires that an insurer’s AI systems program address third-party data and models with the same rigor as internally developed systems. Translation: if your workbench vendor is using third-party ML scoring (Verisk, third-party CAT models, broker-supplied scores), the carrier - not the vendor - has to document the governance.
The third is Executive Order 14365, signed December 11, 2025, which opened a federal-state preemption fight over AI regulation. The NAIC’s December 16, 2025 statement signaled that state regulators are defending their authority and accelerating, not pausing, their AI oversight work. For practical purposes, this means carriers operate under both regimes simultaneously through 2026. The state AI bulletin compliance attestations remain on their existing schedules, and the roughly two dozen states that adopted AI model bulletins before the EO have not withdrawn them.
What does compliance actually require for an underwriting workbench? Five artifacts, all of which the workbench should produce natively rather than retrofit:
A model card documents architecture, training data sources and date ranges, intended use, known limitations, version history, and governance. This is the master reference document for any AI scoring component in the workbench.
A validation report documents training data, accuracy, drift detection, and ongoing monitoring. Not a one-time artifact - a continuously updated record. State market conduct exams in Colorado, Connecticut, New York, and the bulletin-adopting states routinely look back two to three years.
Bias testing documents how protected classes are handled, what fairness metrics are tracked, and what thresholds trigger remediation. The NAIC bulletin specifically requires controls to mitigate the risk of inaccurate, arbitrary, capricious, or unfairly discriminatory outcomes.
Per-decision audit trail captures, for every consequential underwriting decision, which rules fired, which model outputs were considered, what data the model saw, what the underwriter overrode, and why. This is the core compliance artifact. An examiner asking “show me how you made this specific decision” needs an answer in hours, not weeks.
A governance framework documents the model lifecycle: development, validation, deployment, monitoring, retirement. Who has authority to deploy a model. Who has authority to retire one. What the rollback procedure is when a model produces unacceptable results.
State variations matter. California’s regulatory posture has tightened progressively, and California is one of the twelve evaluation tool pilot states. New York DFS has its own circular letter framework that pre-dates and operates alongside the NAIC bulletin. Texas DOI has historically focused examination resources on data accuracy in claims handling, underwriting, and rating practices. Colorado has its own AI governance regulation for life insurers and recently enacted a comprehensive AI framework (with an exemption for insurers subject to existing state regulation). The pattern is increasing fragmentation rather than uniformity, which means a workbench that can configure compliance reporting per jurisdiction is materially less expensive to operate than one that produces a single national report.
For the deeper analysis of explainability requirements specifically, see the next section. For the full compliance playbook including state-by-state variations, see How an underwriting workbench strengthens regulatory compliance.
Explainability requirements: SHAP, LIME, and what regulators actually want
CUOs do not need to understand SHAP values mathematically. They need to be able to point at a screen and tell a regulator: “This applicant was declined because their credit score was below 620 AND their property is in a CAT Tier 4 zone AND they have three or more property claims in the last five years.” That sentence is what explainability looks like in underwriting.
Behind that sentence sits a body of technical methods. SHAP (Shapley Additive Explanations) values quantify each feature’s marginal contribution to a model output, drawing on cooperative game theory to allocate credit for the prediction across input features. LIME (Local Interpretable Model-agnostic Explanations) builds a local linear approximation of a complex model around a specific prediction, making individual decisions individually comprehensible. Partial dependence plots show how predictions change as one feature varies while others are held constant. Counterfactual explanations describe the minimum input change that would flip the prediction.
These methods produce mathematically rigorous descriptions of model behavior. They are useful for model validation and debugging by the data science team. They are not what an examiner reads.
What an examiner reads is regulatory explainability: a written narrative that incorporates outputs from the technical methods but speaks in the examiner’s language - filed factors, rating variables, actuarial justification, regulatory standards. The narrative is what the workbench produces; SHAP and LIME are the inputs that feed the narrative generation.
The architectural question for a CUO evaluating a workbench is not “do you use SHAP?” Every modern workbench can compute SHAP values. The question is “does the workbench produce a regulator-readable explanation document automatically, on demand, for any decision in the audit trail?” If the answer is no, the carrier is exposed to the same compliance retrofitting cost that has hit early-deployment carriers in the AI Systems Evaluation Tool pilot states.
The hybrid pattern wins on every dimension because it pairs the regulatory defensibility of rules with the pattern-detection accuracy of ML, with explainability available at both layers. This is the architecture I recommend to specialty and commercial carriers across the board in 2026.
Build vs buy vs partner: choosing your workbench path
The decision framework below is the one I use in initial conversations with CUOs. There is no universally right answer. There is a right answer for your portfolio, your tech stack, your team’s technical depth, and your timeline. The framework helps you locate where you are.
Build: in-house development of a custom underwriting workbench
Investment: $5-15M USD across a 24-36 month build, plus ongoing engineering of typically 8-15 FTEs to maintain and evolve the platform.
Best fit: Top-10 national carriers with deep internal technology organizations, distinct portfolio characteristics that off-the-shelf vendors don’t address, and the executive willingness to fund a multi-year platform investment. The largest specialty carriers and reinsurers sometimes fall in this bucket because their underwriting logic is genuinely too unique for vendor products to handle without massive customization.
Risk profile: You own the technology. You also own all the technology debt. The build pattern that has consistently failed: a carrier with a strong digital transformation mandate funds a custom workbench, hits roadmap velocity issues in years 2-3, and ends up with a half-built platform that becomes the most expensive way to produce the same operational outcome a vendor product could have delivered.
Buy: licensing an off-the-shelf workbench
Investment: $1-5M USD per year in licensing and implementation services, with deployment timelines of 12-24 months for full production rollout.
Best fit: Mid-tier carriers ($500M-$3B in premium) writing relatively standard P&C lines where the vendor’s reference architecture matches the carrier’s underwriting model with manageable customization. The buy pattern works best when the carrier’s appetite for customization is genuinely modest — if you want the workbench to do things the vendor’s product wasn’t designed for, customization complexity will erode the buy economics fast.
Risk profile: Vendor lock-in is real. Customization limits are real. Implementation timelines that vendors quote (“12 months”) are typically 1.5-2x in practice for any deployment that touches an existing PAS. Plan for it.
Partner: hybrid model with a vendor that provides core platform and configurable customization
Investment: Hybrid pricing — typically a platform license plus configuration services, with the partnership extending into co-development of carrier-specific extensions. Deployment timelines of 6-14 months for production rollout.
Best fit: Specialty and commercial carriers needing customization that buy can’t deliver, without the engineering depth or capital appetite for build. This is the bucket where Decerto and Higson sit. The carriers we work with have specialty portfolios, complex rule logic, and a strong CUO point of view about how the underwriting system should behave — but they are not going to fund a $10M build.
Risk profile: Lower than build, more flexible than buy. The risk shifts to vendor selection: does the partner have the specialty lines expertise, the rule authoring philosophy, and the deployment depth to deliver in 6-14 months? Diligence the partner the way you would diligence a build team.
How to decide
Three questions surface the answer.
- What is your portfolio’s customization requirement? If you write specialty commercial with rule logic that doesn’t compress into a vendor’s reference architecture, buy is going to disappoint you. If you write standard P&C lines, buy is probably the right answer.
- What is your engineering depth? If you have a 200-person engineering organization with a track record of delivering platforms, build is on the table. If you don’t, partnering with someone who does is a better economic answer.
- What is your timeline tolerance? If your CUO needs production capability in 12 months because of NAIC compliance pressure or a senior retirement schedule, build is off the table. Partner is the path that compresses to that timeline.
We see most U.S. mid-tier and specialty carriers landing in the partner bucket in 2026. The economics, the timeline pressure, and the customization requirements line up. To explore whether that’s the right fit for your portfolio, book a 30-minute call directly with me.
ROI metrics: what to measure after deployment
Workbench ROI conversations typically focus on the metric that matters most to the CFO who approved the budget: the loss ratio improvement that justified the investment. The CFO is right to focus there, but six months into deployment, the loss ratio is the noisiest signal you have. It moves on rate adequacy, CAT activity, mix shift, and reserve development - most of which have nothing to do with the workbench. The metrics below are the ones I track in the first 18 months because they predict the loss ratio improvement before the loss ratio itself moves.
Loss ratio improvement is the headline metric. Target: 3-5 points within 12-18 months for a properly scoped deployment. McKinsey research on commercial P&C documents that even leading insurers can capture three to five points of loss ratio improvement and 10-15% new business premium increases through digitized underwriting. The variance is wide. Specialty carriers with significant adverse selection problems sometimes see 7-9 points. Standard P&C carriers with already-disciplined underwriting may see 1-2 points. Set the target against your specific baseline, not the industry headline.
Quote-to-bind conversion moves earlier than loss ratio because it depends on cycle time, not loss emergence. Target: +30-50% within 6 months of production rollout. The mechanism: faster, more accurate quoting wins the broker’s business before competitors respond. This is where the first measurable revenue impact shows up.
Decision time for simple risks is the operational metric that proves the STP architecture works. Baseline at most carriers I’ve worked with: 4 days median from submission to bind on clean BOP renewals. Target post-deployment: 4 hours, with a meaningful share of clean submissions completing in minutes via straight-through processing.
Underwriter productivity measured in policies per underwriter per period. Target: 2-3x within 18 months. The mechanism is not that underwriters are working harder - it’s that the workbench is handling the document extraction and routine evaluation that consumed 60-70% of their day, freeing them for the complex risks where their judgment matters.
Regulatory examination time is the metric that surprises CUOs because it wasn’t part of the original ROI model. Carriers with clean workbench audit trails typically compress regulatory examination response time from 6 weeks to 30 minutes for the data-pull components. The cost saving is real. The strategic value - regulators come back less often when their first inquiry gets a fast, clean response - is larger and harder to put on a spreadsheet.
Adverse selection metrics - measured as the loss ratio differential between submissions written by underwriters at the high end vs. the low end of consistency scoring - should compress materially as the rules engine standardizes the decision floor across the underwriting team. This is one of the cleanest internal validations that the workbench is working: when your most-conservative and least-conservative underwriters start producing similar loss outcomes, the rules are doing their job.
For each metric, the measurement discipline matters more than the metric definition. Establish the baseline before deployment. Pick the comparison window carefully (year-over-year on like-for-like portfolio segments, not point-in-time snapshots). Annotate exogenous events (rate filings, CAT seasons, reinsurance changes) that confound the read. The carriers I see succeed at workbench ROI measurement are the ones that build the measurement discipline before the deployment, not after.
Common implementation failures (and how to avoid them)
The five failure modes I introduced in Section 7 deserve their own deep treatment because they account for the majority of workbench projects that miss their targets. Each one has a specific prevention tactic. None of them are about the technology itself.
Failure 1: Starting with technology rather than portfolio outcomes.
Symptom: the RFP scoring matrix runs against features rather than against loss ratio improvement targets.
Prevention: write the ROI target document - three to five points of loss ratio, +30-50% quote-to-bind, X% reduction in cycle time for clean submissions - before the first vendor demo. Score every vendor response against the target, not against feature checklists. Vendors that can’t connect their features to your specific outcome targets are vendors that haven’t done the work for previous customers either.
Failure 2: Skipping historical data validation.
Symptom: ML risk scoring goes live based on vendor benchmarks. Three months later, the model underperforms on the carrier’s specific portfolio mix because the training data didn’t reflect the carrier’s actual risk distribution.
Prevention: insist on a POC where the vendor’s model runs against your last three to five years of underwriting data. Compare the model’s recommendations against your actual decisions and outcomes. Reject any vendor that won’t do this work pre-contract.
Failure 3: Underestimating change management for senior underwriters.
Symptom: technology works, senior underwriters refuse to use it, the portfolio runs in parallel for years.
Prevention: involve senior underwriters in configuration from month 1, not month 9. Their buy-in is built through participation in rule encoding, not through training sessions delivered after the fact. Carriers that make senior underwriters co-architects of the workbench get sustained adoption. Carriers that make them recipients of the deployment do not.
Failure 4: Black-box ML without explainability.
Symptom: first regulatory inquiry exposes the gap. Compliance retrofitting in production turns out to be six times more expensive than building it in from the start.
Prevention: explainability is a Day 1 requirement, not a Phase 2 enhancement. The model card, validation report, bias testing, per-decision audit trail, and regulator-narrative generation should be configured before the model goes to production. The NAIC AI Systems Evaluation Tool pilot makes this acute: you may face an inquiry inside the deployment period.
Failure 5: Vendor without specialty lines expertise for a specialty book.
Symptom: vendor configures the workbench to fit their reference architecture, which was designed for personal auto. Specialty underwriters find the workbench actively impedes how their lines actually work.
Prevention: in vendor diligence, ask for reference customers that match your line of business specifically. A vendor with strong personal lines references and no specialty references is not the right partner for a specialty book, regardless of how well the demo went.
Frequently asked questions
What is an underwriting workbench in insurance?
An underwriting workbench is a unified workspace where insurance underwriters intake submissions, evaluate risks against rules and AI scoring, document decisions with a full audit trail, and route to bind without leaving a single application. Modern underwriting workbenches replace the patchwork of spreadsheets, PDFs, and disconnected tools that traditionally fragmented underwriting workflow, and add capabilities like document automation, external data integration, explainability, and CUO-controlled rule authoring.
How does AI improve underwriting workbench efficiency in 2026?
AI in a 2026 underwriting workbench operates at three layers: document automation (OCR, NLP, and generative AI extracting structured data from ACORD forms, loss runs, and unstructured submissions); risk scoring (ML models adding pattern detection within rule-defined boundaries); and decision support (AI recommendations the underwriter can accept, override, or escalate). The operational result is straight-through processing for routine risks (4 days collapsing to 4 hours or less), 2-3x underwriter productivity, and 3-5 points of loss ratio improvement when paired with consistent rule enforcement.
What features should an underwriting workbench have for P&C carriers?
The seven non-negotiable features for U.S. P&C carriers in 2026 are: a rules engine with CUO-controlled authoring and governance workflow; hybrid risk scoring combining rules and ML; document automation that handles ACORD, loss runs, and unstructured submissions accurately on real-world (not demo) input; per-decision audit trail meeting NAIC AI Bulletin documentation requirements; external data integration with ISO, CLUE, D&B, Verisk, and CAT modeling; an explainability layer that translates model outputs into regulator-readable narrative; and native Excel integration for actuarial and pricing workflows.
Can AI replace traditional underwriters using a workbench?
No, and the framing has been counterproductive. A modern underwriting workbench operates on a human-in-the-loop architecture: AI handles document extraction, applies rules, and recommends decisions. The underwriter retains authority over consequential bind, decline, and pricing decisions, especially on specialty and complex risks. The capacity AI frees up shifts senior underwriters from document processing - which consumes 60-70% of their day in the legacy workflow - to portfolio strategy, broker relationships, and complex risk evaluation. The replacement framing was driven by hype rather than how carriers actually deploy workbenches.
How does an underwriting workbench integrate with Guidewire or Duck Creek?
Modern workbenches layer on top of existing PAS infrastructure rather than replacing it. Higson, for example, has been deployed at multiple carriers running Guidewire PolicyCenter, Duck Creek Policy, and Majesco - integrating through the PAS APIs without requiring PAS replacement. The integration handles bidirectional data flow: submissions flow from PAS to workbench, decisions flow back to PAS for binding. The workbench owns the underwriting decision logic and audit trail. The PAS owns the policy-of-record. The split lets carriers modernize underwriting without rebuilding their core PAS.
What does NAIC AI Model Bulletin require for underwriting workbenches?
The NAIC AI Model Bulletin, adopted in December 2023 and now in force in over half of U.S. states, requires insurers to maintain a written AI Systems Program addressing governance, risk management, internal controls, model documentation, third-party model oversight, and the prevention of inaccurate, arbitrary, capricious, or unfairly discriminatory outcomes. Practically, an underwriting workbench supports compliance through five artifacts: model card, validation report, bias testing, per-decision audit trail, and governance framework documentation. The NAIC AI Systems Evaluation Tool pilot running through September 2026 in twelve states will examine carriers’ AI governance programs against these requirements.
How long does an underwriting workbench implementation take?
Implementation timelines depend on path: a partner deployment for a specialty carrier typically runs 6-14 months from kickoff to production. An off-the-shelf vendor implementation runs 12-24 months in practice (vendors often quote 12, but PAS integration adds time). A custom build runs 24-36 months and requires sustained engineering depth. The 14-month roadmap covers discovery and requirements (months 1-3), configuration and integration build (4-6), UAT and parallel run (7-9), phased production rollout (10-12), and optimization with ML model deployment (13-14).
What is the difference between rules-based and ML-based underwriting?
Rules-based underwriting encodes underwriting guidelines as executable logic - eligibility, capacity, pricing modifiers, referral triggers - that fires deterministically on every submission. ML-based underwriting uses statistical models trained on historical loss data to score risks based on pattern recognition across many features. Rules are highly defensible to regulators and consistent across the portfolio but brittle to edge cases. ML adds pattern detection that rules miss but creates explainability and regulatory documentation challenges. Most P&C carriers in 2026 run a hybrid: rules define the bright-line decisions and the regulatory boundaries, ML adds pattern detection within those boundaries.
Talk to Decerto and Higson
The market is moving. The NAIC AI Bulletin compliance window narrows every quarter. Senior underwriters are retiring on schedules that don’t wait for IT roadmaps. Competitors who deployed AI underwriting in 2023-2024 are now seeing measurable loss ratio differentials. Each quarter you delay is three to five points of loss ratio not improved, plus compounding regulatory and competitive exposure.
What I offer is a 30-minute portfolio assessment call. Not a sales pitch. The agenda: your portfolio’s specific pain points, your current PAS and tech stack, your NAIC compliance posture, your senior underwriter retirement timeline, your loss ratio targets. By the end of the call, you have a vendor-neutral assessment of which workbench architecture path - build, buy, or partner - fits your situation, and what the realistic timeline and investment look like.
You may be wondering whether your portfolio is too specialty for a workbench approach. We see this concern most often from CUOs at specialty and complex commercial carriers, and it usually reflects bad experiences with workbench vendors whose reference architectures were built for personal auto. Higson is built for specialty and commercial first. The rule logic flexibility, the document automation handling of unstructured submissions, the per-decision audit trail - all of it is architected for the lines where standard vendors struggle.
I have seen carriers go from a 12% straight-through-processing rate on routine submissions to 62% within 18 months of workbench deployment, with corresponding improvements in underwriter productivity and quote-to-bind conversion. The difference between the carriers that achieve those results and the ones that don’t isn’t budget. It’s framework: which path fits the portfolio, which vendor matches the lines, which sequence of rules-then-ML matches the regulatory environment.
We can show you which framework fits your portfolio in 30 minutes.
Book directly with me (Decerto co-founder, 20 years in insurance technology): decerto.com/us/marcinnowak
See Higson rules engine in action: higson.io/download
Sources
- NAIC. “Implementation of NAIC Model Bulletin: Use of Artificial Intelligence Systems by Insurers.”
- NAIC. “NAIC Model Bulletin on the Use of Artificial Intelligence Systems by Insurers” (adopted December 4, 2023).
- NAIC. “Statement from the National Association of Insurance Commissioners on AI Executive Order” (December 16, 2025).
- NAIC. “Big Data and Artificial Intelligence (H) Working Group” (March 2026 sessions).
- Crowell & Moring. “NAIC Intensifies AI Regulatory Focus: What Health Insurance Payors Need to Know” (March 25, 2026).
- S&P Global Market Intelligence. “NAIC membership divided on developing AI model law, disclosure standard” (October 16, 2025).
- Perceptive Analytics. “How P&C Insurers Use Consulting Firms to Improve Combined Ratio” (April 2026).
- Slayton Search. “The Insurance Industry Retirement Crisis: How to Prepare for the Next Wave of Departures” (February 19, 2026).
- InsuranceNewsNet. “Insurance industry retirement exodus creating a talent gap” (July 24, 2025).
- Send Technology. “Underwriting in 2026: margins, human judgement & AI will decide winners” (February 9, 2026).

Subscribe to receive the latest blog posts to your inbox every week.




